{kind=link}
Исследование того, как искусственные агенты могут выбирать действия для достижения целей, быстро развивается благодаря использованию обучения с подкреплением. Подходы без модели к RL, которые учатся предсказывать успешные действия методом проб и ошибок, позволили DQN DeepMind играть в игры Atari и AlphaStar, чтобы побеждать чемпионов мира в Starcraft II, но требуют большого количества взаимодействия с окружающей средой, что ограничивает их полезность для реальных целей. мировые сценарии. Напротив, основанные на модели подходы RL дополнительно изучают упрощенную модель среды. Эта модель мира позволяет агенту прогнозировать результаты возможных последовательностей действий, позволяя ему играть в гипотетических сценариях для принятия обоснованных решений в новых ситуациях, тем самым уменьшая количество проб и ошибок, необходимых для достижения целей.
В прошлом было сложно выучить точные модели мира и использовать их для изучения успешного поведения. Хотя недавние исследования, такие как наша Сеть глубокого планирования (PlaNet), раздвинули эти границы, изучая точные модели мира из изображений, подходы на основе моделей все еще сдерживались неэффективными или дорогостоящими в вычислительном отношении механизмами планирования, ограничивая их способность решать сложные задачи. , Сегодня в сотрудничестве с DeepMind мы представляем Dreamer, RL-агента, который изучает модель мира из изображений и использует ее для изучения дальновидного поведения. Dreamer использует свою мировую модель для эффективного изучения поведения с помощью обратного распространения посредством предсказаний моделей. Научившись вычислять состояния компактной модели из необработанных изображений, агент может эффективно изучать тысячи предсказанных последовательностей параллельно, используя только один графический процессор. Dreamer достигает нового уровня в производительности, эффективности данных и времени вычислений на эталоне из 20 непрерывных задач управления с необработанными входными данными изображения. Чтобы стимулировать дальнейшее продвижение RL, мы выпускаем исходный код для исследовательского сообщества.
Как работает Dreamer?
Dreamer состоит из трех процессов, типичных для методов, основанных на моделях: изучение модели мира, изучение поведения на основе предсказаний, сделанных моделью мира, и выполнение изученного поведения в среде для сбора нового опыта. Для изучения поведения Dreamer использует сеть ценностей для учета выгод, выходящих за рамки планирования, и сеть акторов для эффективного вычисления действий. Три процесса, которые могут выполняться параллельно, повторяются до тех пор, пока агент не достигнет своих целей:
Три процесса агента Мечтателя. Модель мира извлечена из прошлого опыта. Исходя из предсказаний этой модели, агент затем изучает сеть ценностей, чтобы предсказать будущие награды, и сеть акторов, чтобы выбрать действия. Актерская сеть используется для взаимодействия с окружающей средой.
Изучение модели мира
Dreamer использует модель мира PlaNet, которая предсказывает результаты на основе последовательности состояний компактной модели, которые вычисляются из входных изображений, вместо непосредственного прогнозирования от одного изображения к другому. Он автоматически учится создавать модельные состояния, которые представляют концепции, полезные для прогнозирования будущих результатов, таких как типы объектов, положения объектов и взаимодействие объектов с их окружением. Учитывая последовательность изображений, действий и вознаграждений из набора данных оператора из прошлого опыта, Dreamer изучает модель мира, как показано:
Dreamer узнает модель мира из опыта. Используя прошлые изображения (o1 – o3) и действия (a1 – a2), он вычисляет последовательность состояний компактной модели (зеленые кружки), из которых он восстанавливает изображения (ô1 – ô3), и прогнозирует вознаграждение (r̂1 – r̂3).
Преимущество использования модели мира PlaNet заключается в том, что прогнозирование с использованием компактных модельных состояний вместо изображений значительно повышает вычислительную эффективность. Это позволяет модели прогнозировать тысячи последовательностей параллельно на одном графическом процессоре. Этот подход также может облегчить обобщение, что приведет к точным долгосрочным предсказаниям видео. Чтобы получить представление о том, как работает модель, мы можем визуализировать предсказанные последовательности, декодируя состояния компактной модели обратно в изображения, как показано ниже для задачи DeepMind Control Suite и для задачи среды DeepMind Lab:
Прогнозирование с использованием компактных модельных состояний позволяет осуществлять долгосрочные прогнозы в сложных условиях. Здесь показаны две последовательности, с которыми агент не сталкивался ранее. Учитывая пять входных изображений, модель восстанавливает их и прогнозирует будущие изображения до временного шага 50.
Эффективное обучение поведению
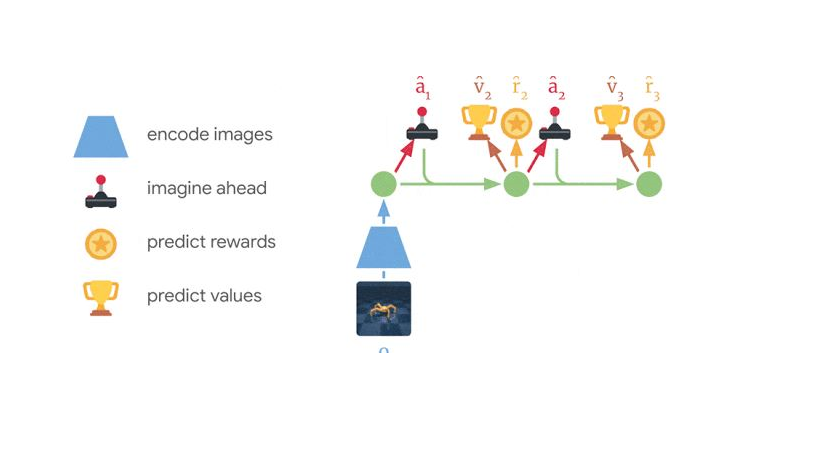
Ранее разработанные агенты на основе моделей обычно выбирают действия либо путем планирования с помощью многих предсказаний модели, либо с помощью модели мира вместо симулятора для повторного использования существующих методов без моделирования. Оба проекта требуют вычислительных усилий и не в полной мере используют модель научного мира. Более того, даже мощные модели мира ограничены в том, насколько далеко они могут точно предсказать, что делает многих предыдущих агентов на основе моделей близорукими. Dreamer преодолевает эти ограничения, изучая ценностную сеть и сеть акторов с помощью обратного распространения через предсказания своей модели мира. Dreamer эффективно изучает сеть актера для прогнозирования успешных действий, распространяя градиенты вознаграждений в обратном направлении через последовательности предсказанных состояний, что невозможно для подходов без моделей. Это говорит Dreamer о том, как небольшие изменения в его действиях влияют на то, какие награды будут предсказаны в будущем, что позволяет ему совершенствовать сеть актеров в направлении, которое больше всего увеличивает вознаграждение. Чтобы рассмотреть вознаграждения за пределами горизонта прогнозирования, сеть ценностей оценивает сумму будущих вознаграждений для каждого состояния модели. Награды и ценности затем распределяются обратно, чтобы уточнить сеть актеров, чтобы выбрать улучшенные действия:
Мечтатель учится дальновидному поведению на основе предсказанных последовательностей модельных состояний. Сначала он изучает долгосрочное значение (v̂2 – v̂3) каждого состояния, а затем прогнозирует действия (â1 – â2), которые приводят к высоким наградам и ценностям, путем обратного распространения их через последовательность состояний в сеть актера
Dreamer отличается от PlaNet несколькими способами. Для конкретной ситуации в среде PlaNet ищет лучшее действие среди множества прогнозов для различных последовательностей действий. Напротив, Dreamer обходит этот дорогой поиск, отделяя планирование и действие. Как только его сеть актеров обучена предсказанным последовательностям, она вычисляет действия для взаимодействия со средой без дополнительного поиска. Кроме того, Dreamer рассматривает вознаграждения за пределами горизонта планирования, используя функцию стоимости, и использует обратное распространение для эффективного планирования.
Производительность по контрольным задачам
Мы оценили Dreamer по стандартному эталону из 20 разнообразных задач с непрерывными действиями и вводом изображений. Задачи включают балансировку и ловлю объектов, а также передвижение различных симулируемых роботов. Задачи предназначены для того, чтобы ставить перед агентом RL различные задачи, в том числе трудно прогнозировать столкновения, редкие награды, хаотическую динамику, небольшие, но важные объекты, высокие степени свободы и трехмерные перспективы:
Dreamer учится решать 20 сложных задач непрерывного управления с помощью входов изображений, 5 из которых отображаются здесь. Визуализации показывают те же изображения 64x64, которые агент получает из среды.
Мы сравниваем производительность Dreamer с производительностью PlaNet, предыдущего лучшего агента на основе моделей, популярного агента без модели A3C, а также лучшего на сегодняшний день агента без модели на этом тесте D4PG, который сочетает в себе несколько достижений модели. Свободная RL. Агенты на основе моделей эффективно обучаются менее чем за 5 миллионов кадров, что соответствует 28 часам внутри моделирования. Агенты без моделей учатся медленнее и требуют 100 миллионов кадров, что соответствует 23 дням внутри моделирования. В тесте из 20 задач Dreamer превосходит лучшего безмодельного агента (D4PG) со средним баллом 823 по сравнению с 786, в то же время обучаясь в 20 раз реже взаимодействию со средой. Более того, он превосходит конечную производительность ранее лучшего агента на основе моделей (PlaNet) практически по всем задачам. Время расчета 16 часов для тренировки Dreamer меньше, чем 24 часа, требуемые для других методов. Окончательная производительность четырех агентов показана ниже:
Dreamer превосходит предыдущие лучшие методы без моделей (D4PG) и моделей (PlaNet) с точки зрения 20 задач с точки зрения конечной производительности, эффективности данных и времени вычислений.
В дополнение к нашим основным экспериментам по задачам непрерывного управления, мы демонстрируем общность Dreamer, применяя его к задачам с дискретными действиями. Для этого мы выбираем игры Atari и уровни DeepMind Lab, которые требуют как реактивного, так и дальновидного поведения, пространственной осведомленности и понимания визуально более разнообразных сцен. Результирующее поведение показано ниже, показывая, что Dreamer также эффективно учится решать эти более сложные задачи:
Dreamer изучает успешное поведение на играх Atari и уровнях DeepMind Lab, которые содержат отдельные действия и визуально более разнообразные сцены, включая трехмерные среды с несколькими объектами.
Заключение
Наша работа демонстрирует, что изучение поведения на основе последовательностей, предсказанных только мировыми моделями, может решить сложные задачи визуального контроля с помощью входных изображений, превосходя производительность предыдущих подходов без моделирования. Кроме того, Dreamer демонстрирует, что обучение поведению путем обратного распространения градиентов значений посредством предсказанных последовательностей состояний компактной модели является успешным и надежным, решая разнообразный набор непрерывных и дискретных задач управления. Мы считаем, что Dreamer предлагает прочную основу для дальнейшего расширения границ обучения с подкреплением, включая лучшее обучение представлению, направленное исследование с оценками неопределенности, временную абстракцию и многозадачное обучение