{kind=link}
Huawei только что объявила, что ее среда MindSpore для разработки приложений для искусственного интеллекта становится открытым исходным кодом и доступна на GiHub и Gitee. MindSpore — это еще одна среда Deep Learning для обучения моделей нейронных сетей, аналогичная TensorFlow или PyTorch, разработанная для использования от Edge до Cloud, которая поддерживает как графические процессоры, так и, очевидно, процессоры Huawei Ascend.
В августе прошлого года, когда Huawei объявил об официальном запуске своего процессора Ascend, впервые был представлен MindSpore, заявив, что «в типичном учебном сеансе на основе ResNet-50 комбинация Ascend 910 и MindSpore происходит примерно в два раза быстрее. При обучении моделей искусственного интеллекта по сравнению с другими основными учебными карточками с использованием TensorFlow Это правда, что в последние годы появилось много фреймворков, и, возможно, MindSpore - не более чем одна из групп, которая даже удаленно может конкурировать с TensorFlow (поддерживается Google) и PyTorch (поддерживается Facebook).
Архитектура системы
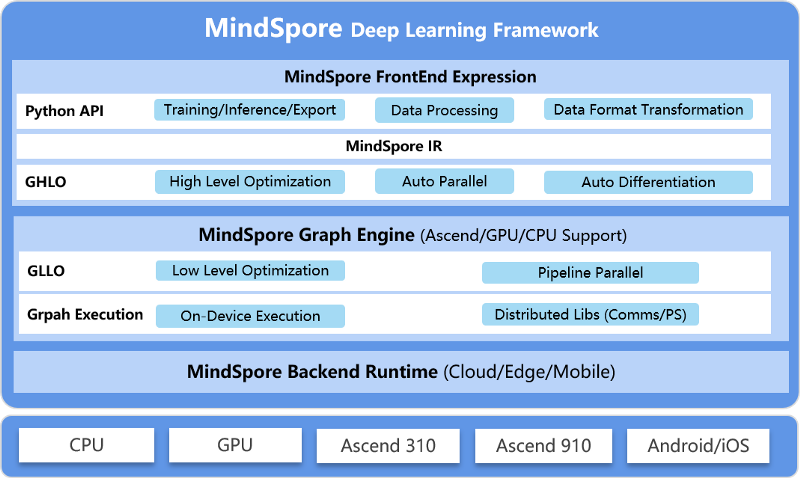
На веб-сайте MindSpore описывается, что инфраструктура состоит из трех основных уровней: выражения внешнего интерфейса, графического движка и среды выполнения бэкенда. На следующем рисунке показана визуальная схема:
Первый уровень MindSpore предлагает Python API для программистов. Поскольку языковой лингвистикой в нашем сообществе является де-факто Python, а в противном случае MindSpore хочет конкурировать с PyTorch и TensorFlow. С помощью этого API программисты могут управлять моделями (обучение, логический вывод и т. Д.) и обрабатывать данные. Этот первый уровень также включает поддержку промежуточного представления кода (MindSpore IR), на котором будет основано множество оптимизаций, которые могут быть выполнены при распараллеливании и автоматическом дифференцировании (GHLO).
Ниже представлен слой Graph Engine, который предлагает необходимые функции для создания и выполнения автоматического дифференцирования графа выполнения. С MindSpore они выбрали модель автоматической дифференциации, отличную от PyTorch (которая создает динамический график выполнения) или TensorFlow (хотя изначально была выбрана возможность создания более эффективного статического графика выполнения, в настоящее время она также предлагает вариант динамического графа выполнения и позволяет использовать статическую версию графа с использованием декоратора @tf.function его низкоуровневого API).
Выбор MindSpore заключается в преобразовании исходного кода в формат промежуточного кода (MindSpore IR), что позволяет использовать преимущества двух моделей (более подробную информацию можно найти в разделе «Автоматическое разграничение» на веб-сайте MindSpore).
Последний уровень состоит из всех библиотек и сред выполнения, необходимых для поддержки различных аппаратных архитектур, в которых будет обрабатываться код. Скорее всего, это будет бэкенд, очень похожий на другой фреймворки, возможно, с особенностями Huawei, например, с такими библиотеками, как HCCL (Библиотека коллективной коммуникации Huawei), эквивалентными NCCL NVIDIA (Библиотека коллективной коммуникации NVIDIA).
Поддержка визуализации тренировочного процесса
Согласно учебному пособию MindSpore, хотя их было невозможно установить и использовать, у них есть MindInsight для создания визуализаций, которые несколько напоминают TensorBoard, TensorFlow. Посмотрите на некоторые скриншоты, которые они показывают на своем сайте:
Согласно руководству, MindSpore в настоящее время использует механизм обратного вызова (напоминающий о том, как это делается с Keras) для записи (в файле журнала) в процессе обучения всех тех параметров и гиперпараметров модели, которые мы хотим, а также графика вычислений, когда компиляция нейронной сети в промежуточный код завершена.
Параллелизм
В своем уроке они говорят о двух режимах распараллеливания (DATA_PARALLEL и AUTO_PARALLEL) и представляют пример кода, который обучает ResNet-50 с набором данных CIFAR для процессора Ascend 910 (который я не смог проверить ). DATA_PARALLEL относится к стратегии, широко известной как параллелизм данных, которая состоит в разделении обучающих данных на несколько подмножеств, каждое из которых выполняется в одной реплике модели, но в разных единицах обработки. Поддержка уровня Graph Engine предоставляется для распараллеливания кодов и, в частности, для параллелизма AUTO_PARALLEL.
Режим AUTO_PARALLEL автоматически оптимизирует распараллеливание, комбинируя стратегию распараллеливания данных (обсуждаемую выше) со стратегией распараллеливания модели, в которой модель делится на разные части, и каждая часть выполняется параллельно в разных блоках обработки. Этот автоматический режим выбирает стратегию распараллеливания, которая предлагает наилучшие преимущества, о чем можно прочитать в разделе «Автоматическая параллель» на веб-сайте MindSpore (хотя они не описывают, как принимаются оценки и решения). Нам придется подождать, чтобы выделить время для технической команды, чтобы расширить документацию и понять больше деталей о стратегии автоматического распараллеливания. Но очевидно, что эта стратегия автоматического распараллеливания имеет решающее значение, и именно здесь они должны и могут конкурировать с TensorFlow или PyTorch, получая значительно более высокую производительность с использованием процессоров Huawei
Запланированная дорожная карта и как внести свой вклад
Очевидно, что предстоит проделать большую работу, и на данный момент они упорядочили идеи, которые они имеют в виду на следующий год, в обширной дорожной карте, представленной на этой странице, но они утверждают, что приоритеты будут скорректированы в соответствии с пользователем.
Обратная связь. На данный момент мы можем найти эти основные линии:
- Поддержка большего количества моделей (ожидающие классические модели, GAN, RNN, Transformers, модели обучения с усилением, вероятностное программирование, AutoML и т. Д.).
- Расширьте API и библиотеки, чтобы улучшить удобство использования и опыт программирования (больше операторов, больше оптимизаторов, больше функций потерь и т. Д.)
- Комплексная поддержка процессора Huawei Ascend и оптимизация его производительности (оптимизация компиляции, улучшение использования ресурсов и т. Д.)
- Эволюция программного стека и выполнение оптимизаций вычислительного графа (улучшение промежуточного представления IR, добавление дополнительных возможностей оптимизации и т. Д.).
- Поддержка большего количества языков программирования (не только Python).
- Улучшение распределенного обучения с оптимизацией автоматического планирования, распределения данных и т. Д.
- Улучшите инструмент MindInsight, чтобы программисту было легче «отлаживать» и улучшать настройку гиперпараметров в процессе обучения.
- Прогресс в предоставлении функциональных возможностей среды логического вывода в устройствах, находящихся в Edge (безопасность, поддержка моделей других платформ через стандарт ONNX и т. Д.)
На странице сообщества вы можете видеть, что у MindSpore есть партнеры за пределами Huawei и Китая, такие как Университет Эдинбурга, Лондонский Имперский колледж, Университет Мюнстера (Германия) или Университет Париж-Сакле. Они говорят, что будут следовать открытой модели управления и предложат всему сообществу внести свой вклад как в код, так и в документацию.
Заключение
После быстрого первого взгляда кажется правильным решение по проектированию и реализации (например, параллелизм и автоматическое дифференцирование), которые могут добавить возможности для улучшений и оптимизаций, которые достигают более высокой производительности, чем структуры, которые они хотят превзойти. Но впереди еще много работы, чтобы поймать PyTorch и TensorFlow, и, прежде всего, создать сообщество, а не просто! Тем не менее, все мы уже знаем, что при поддержке одной крупной компании в секторе, такой как Huawei, все возможно, или это было очевидно три года назад, когда вышла первая версия PyTorch (Facebook), что она может быть близка к пятке TensorFlow (Google)?